![]()
[Aug-2021] Verified Microsoft Exam Dumps with DP-300 Exam Study Guide
Best Quality Microsoft DP-300 Exam Questions TestValid Realistic Practice Exams [2021]
NEW QUESTION 95
You need to implement statistics maintenance for SalesSQLDb1. The solution must meet the technical requirements.
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Answer:
Explanation:
Explanation:
Automating Azure SQL DB index and statistics maintenance using Azure Automation:
1. Create Azure automation account (Step 1)
2. Import SQLServer module (Step 2)
3. Add Credentials to access SQL DB
This will use secure way to hold login name and password that will be used to access Azure SQL DB
4. Add a runbook to run the maintenance (Step 3)
Steps: 1. Click on "runbooks" at the left panel and then click "add a runbook"
2. Choose "create a new runbook" and then give it a name and choose "Powershell" as the type of the runbook and then click on "create"
5. Schedule task (Step 4)
Steps: 1. Click on Schedules 2. Click on "Add a schedule" and follow the instructions to choose existing schedule or create a new schedule.
Reference:
https://techcommunity.microsoft.com/t5/azure-database-support-blog/automating-azure-sql-db-index-and-statistics-maintenance-using/ba-p/368974
NEW QUESTION 96
You have an Azure SQL database named DB3.
You need to provide a user named DevUser with the ability to view the properties of DB3 from Microsoft SQL Server Management Studio (SSMS) as shown in the exhibit. (Click the Exhibit tab.)
Which Transact-SQL command should you run?
- A. GRANT SELECT TO DevUser
- B. GRANT VIEW DATABASE STATE TO DevUser
- C. GRANT VIEW DEFINITION TO DevUser
- D. GRANT SHOWPLAN TO DevUser
Answer: B
Explanation:
The exhibits displays Database [State] properties.
To query a dynamic management view or function requires SELECT permission on object and VIEW SERVER STATE or VIEW DATABASE STATE permission.
Reference:
https://docs.microsoft.com/en-us/sql/relational-databases/databases/database-properties-options-page
NEW QUESTION 97
You have an Azure data factory that has two pipelines named PipelineA and PipelineB.
PipelineA has four activities as shown in the following exhibit.
PipelineB has two activities as shown in the following exhibit.
You create an alert for the data factory that uses Failed pipeline runs metrics for both pipelines and all failure types. The metric has the following settings:
Operator: Greater than
Aggregation type: Total
Threshold value: 2
Aggregation granularity (Period): 5 minutes
Frequency of evaluation: Every 5 minutes
Data Factory monitoring records the failures shown in the following table.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
Reference:
https://docs.microsoft.com/en-us/azure/azure-monitor/alerts/alerts-metric-overview
NEW QUESTION 98
You have an Azure SQL database named db1 on a server named server1.
You need to modify the MAXDOP settings for db1.
What should you do?
- A. Configure the extended properties of db1.
- B. Connect to the master database of server1 and run the sp_configure command.
- C. Connect to db1 and run the sp_configure command.
- D. Modify the database scoped configuration of db1.
Answer: D
Explanation:
Reference:
https://docs.microsoft.com/en-us/azure/azure-sql/database/configure-max-degree-of-parallelism
NEW QUESTION 99
You are designing an enterprise data warehouse in Azure Synapse Analytics that will contain a table named Customers. Customers will contain credit card information.
You need to recommend a solution to provide salespeople with the ability to view all the entries in Customers.
The solution must prevent all the salespeople from viewing or inferring the credit card information.
What should you include in the recommendation?
- A. column-level security
- B. Always Encrypted
- C. row-level security
- D. data masking
Answer: D
Explanation:
Azure SQL Database, Azure SQL Managed Instance, and Azure Synapse Analytics support dynamic data masking. Dynamic data masking limits sensitive data exposure by masking it to non-privileged users.
The Credit card masking method exposes the last four digits of the designated fields and adds a constant string as a prefix in the form of a credit card.
Example:
XXXX-XXXX-XXXX-1234
NEW QUESTION 100
You plan to develop a dataset named Purchases by using Azure Databricks. Purchases will contain the following columns:
ProductID
ItemPrice
LineTotal
Quantity
StoreID
Minute
Month
Hour
Year
Day
You need to store the data to support hourly incremental load pipelines that will vary for each StoreID. The solution must minimize storage costs.
How should you complete the code? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.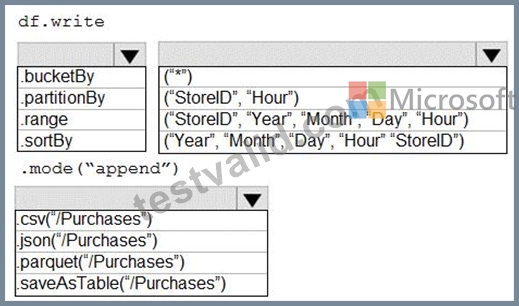
Answer:
Explanation:
Reference:
https://intellipaat.com/community/11744/how-to-partition-and-write-dataframe-in-spark-without-deleting-partitions-with-no-new-data
NEW QUESTION 101
You plan to move two 100-GB databases to Azure.
You need to dynamically scale resources consumption based on workloads. The solution must minimize downtime during scaling operations.
What should you use?
- A. two databases in an Azure SQL Managed instance
- B. two single Azure SQL databases
- C. two databases hosted in SQL Server on an Azure virtual machine
- D. two Azure SQL Databases in an elastic pool
Answer: D
Explanation:
Explanation/Reference:
Explanation:
Azure SQL Database elastic pools are a simple, cost-effective solution for managing and scaling multiple databases that have varying and unpredictable usage demands. The databases in an elastic pool are on a single server and share a set number of resources at a set price.
Reference:
https://docs.microsoft.com/en-us/azure/azure-sql/database/elastic-pool-overview
NEW QUESTION 102
You plan to move two 100-GB databases to Azure.
You need to dynamically scale resources consumption based on workloads.
The solution must minimize downtime during scaling operations.
What should you use?
- A. an Azure SQL Database managed instance
- B. Azure SQL databases
- C. An Azure SQL Database elastic pool
- D. SQL Server on Azure virtual machines
Answer: C
NEW QUESTION 103
You need to implement authentication for ResearchDB1. The solution must meet the security and compliance requirements.
What should you run as part of the implementation?
- A. CREATE USER and the FROM LOGIN clause
- B. CREATE USER and the FROM EXTERNAL PROVIDER clause
- C. CREATE USER and the ASYMMETRIC KEY clause
- D. CREATE USER and the FROM CERTIFICATE clause
- E. CREATE LOGIN and the FROM WINDOWS clause
Answer: B
Explanation:
Scenario: Authenticate database users by using Active Directory credentials.
(Create a new Azure SQL database named ResearchDB1 on a logical server named ResearchSrv01.) Authenticate the user in SQL Database or SQL Data Warehouse based on an Azure Active Directory user:
CREATE USER [[email protected]] FROM EXTERNAL PROVIDER;
Reference:
https://docs.microsoft.com/en-us/sql/t-sql/statements/create-user-transact-sql Perform Administration by Using T-SQL Question Set 2
NEW QUESTION 104
You are designing a star schema for a dataset that contains records of online orders. Each record includes an order date, an order due date, and an order ship date.
You need to ensure that the design provides the fastest query times of the records when querying for arbitrary date ranges and aggregating by fiscal calendar attributes.
Which two actions should you perform? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
- A. Create a date dimension table that has a DateTime key.
- B. Use built-in SQL functions to extract date attributes.
- C. Use DateTime columns for the date fields.
- D. Create a date dimension table that has an integer key in the format of YYYYMMDD.
- E. Use integer columns for the date fields.
Answer: D,E
Explanation:
Reference:
https://community.idera.com/database-tools/blog/b/community_blog/posts/why-use-a-date-dimension-table-ina-data-warehouse
NEW QUESTION 105
You have an Azure SQL database.
You identify a long running query.
You need to identify which operation in the query is causing the performance issue.
What should you use to display the query execution plan in Microsoft SQL Server Management Studio (SSMS)?
- A. Live Query Statistics
- B. Client Statistics
- C. an estimated execution plan
- D. an actual execution plan
Answer: D
Explanation:
To include an execution plan for a query during execution
1. On the SQL Server Management Studio toolbar, click Database Engine Query. You can also open an existing query and display the estimated execution plan by clicking the Open File toolbar button and locating the existing query.
2. Enter the query for which you would like to display the actual execution plan.
3. On the Query menu, click Include Actual Execution Plan or click the Include Actual Execution Plan toolbar button.
Note: Actual execution plans are generated after the Transact-SQL queries or batches execute. Because of this, an actual execution plan contains runtime information, such as actual resource usage metrics and runtime warnings (if any). The execution plan that is generated displays the actual query execution plan that the SQL Server Database Engine used to execute the queries.
Reference:
https://docs.microsoft.com/en-us/sql/relational-databases/performance/display-an-actual-execution-plan
NEW QUESTION 106
HOTSPOT
You have an Azure SQL database named db1.
You need to retrieve the resource usage of db1 from the last week.
How should you complete the statement? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Answer:
Explanation:
Explanation:
Box 1: sys.resource_stats
sys.resource_stats returns CPU usage and storage data for an Azure SQL Database. It has database_name and start_time columns.
Box 2: DateAdd
The following example returns all databases that are averaging at least 80% of compute utilization over the last one week.
DECLARE @s datetime;
DECLARE @e datetime;
SET @s= DateAdd(d,-7,GetUTCDate());
SET @e= GETUTCDATE();
SELECT database_name, AVG(avg_cpu_percent) AS Average_Compute_Utilization FROM sys.resource_stats WHERE start_time BETWEEN @s AND @e GROUP BY database_name HAVING AVG(avg_cpu_percent) >= 80 Incorrect Answers:
sys.dm_exec_requests:
sys.dm_exec_requests returns information about each request that is executing in SQL Server. It does not have a column named database_name.
sys.dm_db_resource_stats:
sys.dm_db_resource_stats does not have any start_time column.
Note: sys.dm_db_resource_stats returns CPU, I/O, and memory consumption for an Azure SQL Database database. One row exists for every 15 seconds, even if there is no activity in the database. Historical data is maintained for approximately one hour.
Sys.dm_user_db_resource_governance returns actual configuration and capacity settings used by resource governance mechanisms in the current database or elastic pool. It does not have any start_time column.
Reference:
https://docs.microsoft.com/en-us/sql/relational-databases/system-catalog-views/sys-resource-stats-azure-sql- database Optimize Query Performance Testlet 1 This is a case study. Case studies are not timed separately. You can use as much exam time as you would like to complete each case. However, there may be additional case studies and sections on this exam. You must manage your time to ensure that you are able to complete all questions included on this exam in the time provided.
To answer the questions included in a case study, you will need to reference information that is provided in the case study. Case studies might contain exhibits and other resources that provide more information about the scenario that is described in the case study. Each question is independent of the other questions in this case study.
At the end of this case study, a review screen will appear. This screen allows you to review your answers and to make changes before you move to the next section of the exam. After you begin a new section, you cannot return to this section.
To start the case study
To display the first question in this case study, click the Next button. Use the buttons in the left pane to explore the content of the case study before you answer the questions. Clicking these buttons displays information such as business requirements, existing environment, and problem statements. If the case study has an All Information tab, note that the information displayed is identical to the information displayed on the subsequent tabs. When you are ready to answer a question, click the Question button to return to the question.
Existing Environment
Network Environment
The manufacturing and research datacenters connect to the primary datacenter by using a VPN.
The primary datacenter has an ExpressRoute connection that uses both Microsoft peering and private peering.
The private peering connects to an Azure virtual network named HubVNet.
Identity Environment
Litware has a hybrid Azure Active Directory (Azure AD) deployment that uses a domain named litwareinc.com.
All Azure subscriptions are associated to the litwareinc.com Azure AD tenant.
Database Environment
The sales department has the following database workload:
* An on-premises named SERVER1 hosts an instance of Microsoft SQL Server 2012 and two 1-TB databases.
* A logical server named SalesSrv01A contains a geo-replicated Azure SQL database named SalesSQLDb1.
SalesSQLDb1 is in an elastic pool named SalesSQLDb1Pool. SalesSQLDb1 uses database firewall rules and contained database users.
* An application named SalesSQLDb1App1 uses SalesSQLDb1.
The manufacturing office contains two on-premises SQL Server 2016 servers named SERVER2 and SERVER3. The servers are nodes in the same Always On availability group. The availability group contains a database named ManufacturingSQLDb1 Database administrators have two Azure virtual machines in HubVnet named VM1 and VM2 that run Windows Server 2019 and are used to manage all the Azure databases.
Licensing Agreement
Litware is a Microsoft Volume Licensing customer that has License Mobility through Software Assurance.
Current Problems
SalesSQLDb1 experiences performance issues that are likely due to out-of-date statistics and frequent blocking queries.
Requirements
Planned Changes
Litware plans to implement the following changes:
* Implement 30 new databases in Azure, which will be used by time-sensitive manufacturing apps that have varying usage patterns. Each database will be approximately 20 GB.
* Create a new Azure SQL database named ResearchDB1 on a logical server named ResearchSrv01.
ResearchDB1 will contain Personally Identifiable Information (PII) data.
* Develop an app named ResearchApp1 that will be used by the research department to populate and access ResearchDB1.
* Migrate ManufacturingSQLDb1 to the Azure virtual machine platform.
* Migrate the SERVER1 databases to the Azure SQL Database platform.
Technical Requirements
Litware identifies the following technical requirements:
* Maintenance tasks must be automated.
* The 30 new databases must scale automatically.
* The use of an on-premises infrastructure must be minimized.
* Azure Hybrid Use Benefits must be leveraged for Azure SQL Database deployments.
* All SQL Server and Azure SQL Database metrics related to CPU and storage usage and limits must be analyzed by using Azure built-in functionality.
Security and Compliance Requirements
Litware identifies the following security and compliance requirements:
* Store encryption keys in Azure Key Vault.
* Retain backups of the PII data for two months.
* Encrypt the PII data at rest, in transit, and in use.
* Use the principle of least privilege whenever possible.
* Authenticate database users by using Active Directory credentials.
* Protect Azure SQL Database instances by using database-level firewall rules.
* Ensure that all databases hosted in Azure are accessible from VM1 and VM2 without relying on public endpoints.
Business Requirements
Litware identifies the following business requirements:
* Meet an SLA of 99.99% availability for all Azure deployments.
* Minimize downtime during the migration of the SERVER1 databases.
* Use the Azure Hybrid Use Benefits when migrating workloads to Azure.
* Once all requirements are met, minimize costs whenever possible.
NEW QUESTION 107
You have an Azure Synapse Analytics Apache Spark pool named Pool1.
You plan to load JSON files from an Azure Data Lake Storage Gen2 container into the tables in Pool1. The structure and data types vary by file.
You need to load the files into the tables. The solution must maintain the source data types.
What should you do?
- A. Load the data by using PySpark.
- B. Use a Get Metadata activity in Azure Data Factory.
- C. Load the data by using the OPENROWSET Transact-SQL command in an Azure Synapse Analytics serverless SQL pool.
- D. Use a Conditional Split transformation in an Azure Synapse data flow.
Answer: C
Explanation:
Serverless SQL pool can automatically synchronize metadata from Apache Spark. A serverless SQL pool database will be created for each database existing in serverless Apache Spark pools.
Serverless SQL pool enables you to query data in your data lake. It offers a T-SQL query surface area that accommodates semi-structured and unstructured data queries.
To support a smooth experience for in place querying of data that's located in Azure Storage files, serverless SQL pool uses the OPENROWSET function with additional capabilities.
The easiest way to see to the content of your JSON file is to provide the file URL to the OPENROWSET function, specify csv FORMAT.
Reference:
https://docs.microsoft.com/en-us/azure/synapse-analytics/sql/query-json-files
https://docs.microsoft.com/en-us/azure/synapse-analytics/sql/query-data-storage
NEW QUESTION 108
You have an Azure SQL Database managed instance named sqldbmi1 that contains a database name Sales.
You need to initiate a backup of Sales.
How should you complete the Transact-SQL statement? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
Reference:
https://techcommunity.microsoft.com/t5/azure-sql-database/native-database-backup-in-azure-sql-managed-instance/ba-p/386154
NEW QUESTION 109
You have an Azure SQL database named DB1. You run a query while connected to DB1.
You review the actual execution plan for the query, and you add an index to a table referenced by the query.
You need to compare the previous actual execution plan for the query to the Live Query Statistics.
What should you do first in Microsoft SQL Server Management Studio (SSMS)?
- A. Run the SET SHOWPLAN_ALLTransact-SQL statement.
- B. Enable Query Store for DB1.
- C. Save the actual execution plan.
- D. For DB1, set QUERY_CAPTURE_MODE of Query Store to All.
Answer: C
Explanation:
The Plan Comparison menu option allows side-by-side comparison of two different execution plans, for easier identification of similarities and changes that explain the different behaviors for all the reasons stated above.
This option can compare between:
Two previously saved execution plan files (.sqlplan extension).
One active execution plan and one previously saved query execution plan.
Two selected query plans in Query Store.
NEW QUESTION 110
You have a new Azure SQL database. The database contains a column that stores confidential information.
You need to track each time values from the column are returned in a query. The tracking information must be stored for 365 days from the date the query was executed.
Which three actions should you perform? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
- A. Turn on Azure Advanced Threat Protection (ATP).
- B. Apply sensitivity labels named Highly Confidential to the column.
- C. Turn on auditing and write audit logs to an Azure Storage account.
- D. Add extended properties to the column.
- E. Turn on Advanced Data Security for the Azure SQL server.
Answer: B,C,E
Explanation:
C: Advanced Data Security (ADS) is a unified package for advanced SQL security capabilities. ADS is available for Azure SQL Database, Azure SQL Managed Instance, and Azure Synapse Analytics. It includes functionality for discovering and classifying sensitive data D: You can apply sensitivity-classification labels persistently to columns by using new metadata attributes that have been added to the SQL Server database engine. This metadata can then be used for advanced, sensitivity-based auditing and protection scenarios.
A: An important aspect of the information-protection paradigm is the ability to monitor access to sensitive data. Azure SQL Auditing has been enhanced to include a new field in the audit log called data_sensitivity_information. This field logs the sensitivity classifications (labels) of the data that was returned by a query. Here's an example:
Reference:
https://docs.microsoft.com/en-us/azure/azure-sql/database/data-discovery-and-classification-overview
NEW QUESTION 111
Which audit log destination should you use to meet the monitoring requirements?
- A. Azure Log Analytics
- B. Azure Event Hubs
- C. Azure Storage
Answer: A
Explanation:
Scenario: Use a single dashboard to review security and audit data for all the PaaS databases.
With dashboards can bring together operational data that is most important to IT across all your Azure resources, including telemetry from Azure Log Analytics.
Note: Auditing for Azure SQL Database and Azure Synapse Analytics tracks database events and writes them to an audit log in your Azure storage account, Log Analytics workspace, or Event Hubs.
Reference:
https://docs.microsoft.com/en-us/azure/azure-monitor/visualize/tutorial-logs-dashboards
Topic 2, Litware
Existing Environment
Network Environment
The manufacturing and research datacenters connect to the primary datacenter by using a VPN.
The primary datacenter has an ExpressRoute connection that uses both Microsoft peering and private peering. The private peering connects to an Azure virtual network named HubVNet.
Identity Environment
Litware has a hybrid Azure Active Directory (Azure AD) deployment that uses a domain named litwareinc.com. All Azure subscriptions are associated to the litwareinc.com Azure AD tenant.
Database Environment
The sales department has the following database workload:
An on-premises named SERVER1 hosts an instance of Microsoft SQL Server 2012 and two 1-TB databases.
A logical server named SalesSrv01A contains a geo-replicated Azure SQL database named SalesSQLDb1. SalesSQLDb1 is in an elastic pool named SalesSQLDb1Pool. SalesSQLDb1 uses database firewall rules and contained database users.
An application named SalesSQLDb1App1 uses SalesSQLDb1.
The manufacturing office contains two on-premises SQL Server 2016 servers named SERVER2 and SERVER3. The servers are nodes in the same Always On availability group. The availability group contains a database named ManufacturingSQLDb1 Database administrators have two Azure virtual machines in HubVnet named VM1 and VM2 that run Windows Server 2019 and are used to manage all the Azure databases.
Licensing Agreement
Litware is a Microsoft Volume Licensing customer that has License Mobility through Software Assurance.
Current Problems
SalesSQLDb1 experiences performance issues that are likely due to out-of-date statistics and frequent blocking queries.
Requirements
Planned Changes
Litware plans to implement the following changes:
Implement 30 new databases in Azure, which will be used by time-sensitive manufacturing apps that have varying usage patterns. Each database will be approximately 20 GB.
Create a new Azure SQL database named ResearchDB1 on a logical server named ResearchSrv01. ResearchDB1 will contain Personally Identifiable Information (PII) data.
Develop an app named ResearchApp1 that will be used by the research department to populate and access ResearchDB1.
Migrate ManufacturingSQLDb1 to the Azure virtual machine platform.
Migrate the SERVER1 databases to the Azure SQL Database platform.
Technical Requirements
Litware identifies the following technical requirements:
Maintenance tasks must be automated.
The 30 new databases must scale automatically.
The use of an on-premises infrastructure must be minimized.
Azure Hybrid Use Benefits must be leveraged for Azure SQL Database deployments.
All SQL Server and Azure SQL Database metrics related to CPU and storage usage and limits must be analyzed by using Azure built-in functionality.
Security and Compliance Requirements
Litware identifies the following security and compliance requirements:
Store encryption keys in Azure Key Vault.
Retain backups of the PII data for two months.
Encrypt the PII data at rest, in transit, and in use.
Use the principle of least privilege whenever possible.
Authenticate database users by using Active Directory credentials.
Protect Azure SQL Database instances by using database-level firewall rules.
Ensure that all databases hosted in Azure are accessible from VM1 and VM2 without relying on public endpoints.
Business Requirements
Litware identifies the following business requirements:
Meet an SLA of 99.99% availability for all Azure deployments.
Minimize downtime during the migration of the SERVER1 databases.
Use the Azure Hybrid Use Benefits when migrating workloads to Azure.
Once all requirements are met, minimize costs whenever possible.
NEW QUESTION 112
What should you implement to meet the disaster recovery requirements for the PaaS solution?
- A. Availability Zones
- B. Always On availability groups
- C. geo-replication
- D. failover groups
Answer: D
Explanation:
Section: [none]
Explanation:
Scenario: In the event of an Azure regional outage, ensure that the customers can access the PaaS solution
with minimal downtime. The solution must provide automatic failover.
The auto-failover groups feature allows you to manage the replication and failover of a group of databases on a
server or all databases in a managed instance to another region. It is a declarative abstraction on top of the
existing active geo-replication feature, designed to simplify deployment and management of geo-replicated
databases at scale. You can initiate failover manually or you can delegate it to the Azure service based on a
user-defined policy.
The latter option allows you to automatically recover multiple related databases in a secondary region after a
catastrophic failure or other unplanned event that results in full or partial loss of the SQL Database or SQL
Managed Instance availability in the primary region.
Reference:
https://docs.microsoft.com/en-us/azure/azure-sql/database/auto-failover-group-overview
Question Set 3
NEW QUESTION 113
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have SQL Server 2019 on an Azure virtual machine.
You are troubleshooting performance issues for a query in a SQL Server instance.
To gather more information, you query sys.dm_exec_requests and discover that the wait type is PAGELATCH_UP and the wait_resource is 2:3:905856.
You need to improve system performance.
Solution: You reduce the use of table variables and temporary tables.
Does this meet the goal?
- A. No
- B. Yes
Answer: B
Explanation:
Reference:
https://docs.microsoft.com/en-US/troubleshoot/sql/performance/recommendations-reduce-allocation-contention
NEW QUESTION 114
You have an Azure SQL database. The database contains a table that uses a columnstore index and is
accessed infrequently.
You enable columnstore archival compression.
What are two possible results of the configuration? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
- A. Queries that use the index will consume more CPU resources.
- B. Queries that use the index will consume more disk I/O.
- C. The index will consume more memory.
- D. Queries that use the index will retrieve fewer data pages.
- E. The index will consume more disk space.
Answer: A,D
Explanation:
Section: [none]
Explanation:
For rowstore tables and indexes, use the data compression feature to help reduce the size of the database. In
addition to saving space, data compression can help improve performance of I/O intensive workloads because
the data is stored in fewer pages and queries need to read fewer pages from disk.
Use columnstore archival compression to further reduce the data size for situations when you can afford extra
time and CPU resources to store and retrieve the data.
Testlet 1
Case study
This is a case study. Case studies are not timed separately. You can use as much exam time as you
would like to complete each case. However, there may be additional case studies and sections on this exam.
You must manage your time to ensure that you are able to complete all questions included on this exam in the
time provided.
To answer the questions included in a case study, you will need to reference information that is provided in the
case study. Case studies might contain exhibits and other resources that provide more information about the
scenario that is described in the case study. Each question is independent of the other questions in this case
study.
At the end of this case study, a review screen will appear. This screen allows you to review your answers and to
make changes before you move to the next section of the exam. After you begin a new section, you cannot
return to this section.
To start the case study
To display the first question in this case study, click the Next button. Use the buttons in the left pane to explore
the content of the case study before you answer the questions. Clicking these buttons displays information such
as business requirements, existing environment, and problem statements. If the case study has an All
Information tab, note that the information displayed is identical to the information displayed on the subsequent
tabs. When you are ready to answer a question, click the Question button to return to the question.
Overview
Litware, Inc. is a renewable energy company that has a main office in Boston. The main office hosts a sales
department and the primary datacenter for the company.
Physical Locations
Existing Environment
Litware has a manufacturing office and a research office is separate locations near Boston. Each office has its
own datacenter and internet connection.
The manufacturing and research datacenters connect to the primary datacenter by using a VPN.
Network Environment
The primary datacenter has an ExpressRoute connection that uses both Microsoft peering and private peering.
The private peering connects to an Azure virtual network named HubVNet.
Identity Environment
Litware has a hybrid Azure Active Directory (Azure AD) deployment that uses a domain named litwareinc.com.
All Azure subscriptions are associated to the litwareinc.com Azure AD tenant.
Database Environment
The sales department has the following database workload:
* An on-premises named SERVER1 hosts an instance of Microsoft SQL Server 2012 and two 1-TB
databases.
* A logical server named SalesSrv01A contains a geo-replicated Azure SQL database named SalesSQLDb1,
SalesSQLDb1 is in an elastic pool named SalesSQLDb1Pool. SalesSQLDb1 uses database firewall rules
and contained database users.
* An application named SalesSQLDb1App1 uses SalesSQLDb1.
The manufacturing office contains two on-premises SQL Server 2016 servers named SERVER2 and
SERVER3. The servers are nodes in the same Always On availability group. The availability group contains a
database named ManufacturingSQLDb1.
Database administrators have two Azure virtual machines in HubVnet named VM1 and VM2 that run Windows
Server 2019 and are used to manage all the Azure databases.
Licensing Agreement
Litware is a Microsoft Volume Licensing customer that has License Mobility through Software Assurance.
Current Problems
Requirements
SalesSQLDb1 experiences performance issues that are likely due to out-of-date statistics and frequent blocking
queries.
Planned Changes
Litware plans to implement the following changes:
* Implement 30 new databases in Azure, which will be used by time-sensitive manufacturing apps that have
varying usage patterns. Each database will be approximately 20 GB.
* Create a new Azure SQL database named ResearchDB1 on a logical server named ResearchSrv01.
ResearchDB1 will contain Personally Identifiable Information (PII) data.
* Develop an app named ResearchApp1 that will be used by the research department to populate and access
ResearchDB1.
* Migrate ManufacturingSQLDb1 to the Azure virtual machine platform.
* Migrate the SERVER1 databases to the Azure SQL Database platform.
Technical Requirements
Litware identifies the following technical requirements:
* Maintenance tasks must be automated.
* The 30 new databases must scale automatically.
* The use of an on-premises infrastructure must be minimized.
* Azure Hybrid Use Benefits must be leveraged for Azure SQL Database deployments.
* All SQL Server and Azure SQL Database metrics related to CPU and storage usage and limits must be
analyzed by using Azure built-in functionality.
Security and Compliance Requirements
Litware identifies the following security and compliance requirements:
* Store encryption keys in Azure Key Vault.
* Retain backups of the PII data for two months.
* Encrypt the PII data at rest, in transit, and in use.
* Use the principle of least privilege whenever possible.
* Authenticate database users by using Active Directory credentials.
* Protect Azure SQL Database instances by using database-level firewall rules.
* Ensure that all databases hosted in Azure are accessible from VM1 and VM2 without relying on public
endpoints.
Business Requirements
Litware identifies the following business requirements:
* Meet an SLA of 99.99% availability for all Azure deployments.
* Minimize downtime during the migration of the SERVER1 databases.
* Use the Azure Hybrid Use Benefits when migrating workloads to Azure.
* Once all requirements are met, minimize costs whenever possible.
NEW QUESTION 115
You have 50 Azure SQL databases.
You need to notify the database owner when the database settings, such as the database size and pricing tier,
are modified in Azure.
What should you do?
- A. Create an alert rule that uses a Metric signal type.
- B. For the database, create a diagnostic setting that has the InstanceAndAppAdvanced metric enabled.
- C. Create an alert rule that uses an Activity Log signal type.
- D. Create a diagnostic setting for the activity log that has the Security log enabled.
Answer: C
Explanation:
Section: [none]
Explanation:
Activity log events - An alert can trigger on every event, or, only when a certain number of events occur.
Incorrect Answers:
C: Metric values - The alert triggers when the value of a specified metric crosses a threshold you assign in
either direction. That is, it triggers both when the condition is first met and then afterwards when that condition
is no longer being met.
Reference:
https://docs.microsoft.com/en-us/azure/azure-sql/database/alerts-insights-configure-portal
NEW QUESTION 116
......
Authentic Best resources for DP-300: https://www.testvalid.com/DP-300-exam-collection.html
DP-300 Test Engine Practice Exam: https://drive.google.com/open?id=1upRGxaNwdQ6dfOJUSGmV4cPwMtovv-jk